GPT와 함께 아래 내용들을 정리했습니다.

2025년 1월, 핫하게 떠오른 DeepSeek 모델
최근 AI 업계에서 뜨거운 화제가 되고 있는 DeepSeek 모델을 살펴보자.
이 모델은 헤지펀드 하이 플라이어 퀀트라는 기업에서 개발한 것으로, 해당 기업은 550만 달러의 비용으로 현재까지 가장 뛰어난 오픈 소스 언어 모델을 만들었다고 주장하고 있다.
NVIDIA 칩 의존도를 낮춘 혁신
DeepSeek 개발진은 "꼭 최고의 NVIDIA 칩이 아니더라도 고성능 모델을 개발할 수 있다"라고 자신 있게 발표했다.
실제로 DeepSeek은 오픈 소스 모델 중 최고의 성능을 기록했으며, 폐쇄형 모델인 GPT-4와도 견줄 만한 결과를 보여주었다.
이 혁신적인 접근은 업계 전반에 큰 반향을 일으켰으며, 특히 NVIDIA의 주가에 직접적인 영향을 미쳤다.
NVIDIA 주가에 미친 영향
DeepSeek의 성공으로 인해 NVIDIA의 칩 독점 체제에 도전이 시작되었고, 이에 따라 NVIDIA의 시가총액이 3% 하락했다는 분석이 나오고 있다.
이는 DeepSeek의 성능이 단순한 기술적 성과를 넘어, GPU 하드웨어 시장의 패러다임 변화를 예고하고 있음을 보여준다.

DeepSeek-V3
6710억 개의 파라미터를 가진 Mixture-of-Experts(MoE) 기반의 대규모 언어 모델로, 뛰어난 성능과 효율성을 자랑합니다.
1. DeepSeek-V3의 핵심 특징
1.1. 효율적인 Mixture-of-Experts (MoE) 아키텍처

- 활성화 파라미터 최적화: 각 토큰마다 활성화되는 파라미터는 370억 개로 제한되어, 계산 효율성을 높이면서도 높은 성능을 유지.
- Multi-head Latent Attention (MLA): 기존 MoE 모델의 한계를 극복하기 위해 채택된 MLA 구조는 모델의 추론 효율성을 극대화.
- 효율적인 추론을 가능하게 하며, DeepSeek-V2에서도 검증된 구조.
1.2. 혁신적인 부하 균형 전략
- 부가 손실 없는 부하 균형(Auxiliary-Loss-Free Load Balancing):
- 부하 균형을 유지하면서 성능 저하를 최소화하는 전략으로 모델의 안정성과 성능 향상을 동시에 달성.
- 멀티 토큰 예측 학습
- 단일 토큰 예측을 넘어서는 학습 목표로, 평가 벤치마크에서 모델의 성능을 크게 향상.
- 추론 단계에서 Speculative Decoding을 통해 추론 속도 향상 가능.
1.3. 광범위한 데이터 학습
- 14.8조 개의 고품질 토큰: 다양하고 방대한 데이터셋을 활용한 사전 학습을 통해 언어 이해 능력을 극대화.
1.4. 안정적인 학습
- 효율적인 학습 시간:
- 14.8조 개의 고품질 토큰 학습: 학습 데이터의 품질과 다양성을 확보하여 모델의 언어 이해 능력을 극대화. .
- 2.788M GPU 시간: 전체 학습 비용은 278만 8천 GPU 시간($5.576M)으로, 기존 대규모 모델 대비 경제적.
- Pre-Training: 2664K GPU 시간
- Context Extension: 119K GPU 시간
- Post-Training: 5K GPU 시간

- 안정성 보장: 학습 과정에서 손실 스파이크나 회복 불가능한 오류 없이 일관된 학습 환경 유지.
1.5 학습 및 평가 과정
1. 사전 학습(Pre-Training): 모델의 기본 실력을 키우는 과정
DeepSeek-V3는 기본기를 탄탄히 하기 위해 특별한 학습 기술을 도입했습니다.
- FP8 정밀도 학습:
- FP8이라는 새로운 계산 방식을 사용해 속도를 빠르게 하고 메모리 소모를 줄였습니다.
- 특히, 이런 방식을 대규모 모델 학습에 성공적으로 적용한 첫 사례로 주목받고 있습니다.
- DualPipe와 메모리 최적화:
- 모델 학습 중 불필요한 시간 낭비를 줄이기 위해 여러 작업을 동시에 처리하는 효율적인 구조를 적용했습니다.
- 메모리 사용을 똑똑하게 관리해 한 번에 더 많은 데이터를 처리할 수 있게 되었죠.
2. 문맥 길이 확장(Context Length Extension): 긴 글도 잘 이해하도록 훈련
DeepSeek-V3는 처음에는 한 번에 32,000자까지 이해할 수 있었지만, 이후 학습을 통해 128,000자까지 문맥을 확장했습니다.
이 덕분에 긴 문서나 대화도 자연스럽게 처리할 수 있는 능력을 갖추게 되었습니다.
3. 지도 학습 및 강화 학습(Post-Training): 사람처럼 자연스러운 대화 능력 강화
이 단계에서는 모델이 사람과의 대화에서 더 똑똑하고 유연한 답변을 할 수 있도록 추가로 훈련했습니다.
- 지식 증류(Knowledge Distillation):
- 이전 DeepSeek-R1 모델의 강점을 학습해 복잡한 문제를 해결하는 능력을 더욱 강화했습니다.
- 사용자 친화적 답변 설계:
- 답변 스타일과 길이를 조절할 수 있도록 설계하여 사용자가 원하는 대로 간결하거나 상세한 답변을 받을 수 있게 했습니다.
2. 아키텍처 상세
2.1. 기본 아키텍처
DeepSeek-V3는 Transformer 아키텍처를 기반으로 하며, 다음과 같은 기술적 특징을 가지고 있습니다:
1. Multi-Head Latent Attention (MLA):
- Attention 구조에서 키(Key)와 값(Value)을 효율적으로 압축하여 KV 캐시 사용량을 줄이는 기법입니다.
- 기존 Transformer의 Multi-Head Attention(MHA)과 비슷한 성능을 유지하면서도 메모리와 계산 비용을 크게 절감합니다.

즉, MLA는 Key와 Value를 압축 및 복원하는 과정을 추가하여, 기존 MHA 대비 메모리 사용량을 크게 줄이면서도 동일한 수식 구조와 성능을 유지합니다. 특히, 긴 입력 시퀀스를 처리해야 하는 대규모 언어 모델에서 큰 이점을 제공합니다.
2. DeepSeekMoE Loss (Mixture-of-Experts):
- MoE 구조를 활용해 모델의 계산 성능을 극대화하며, 효율적인 부하 균형(Auxiliary-Loss-Free Load Balancing) 전략을 새롭게 도입했습니다.
2.1 부하 균형 문제
- 문제점: MoE 모델에서 특정 전문가(Expert)에 작업이 편중되면, 라우팅 효율성이 감소하고 계산 자원이 비효율적으로 사용될 수 있습니다.
- 기존 방법: 부가 손실(Auxiliary Loss)을 추가하여 부하 균형을 맞추는 방식이 사용되었으나, 이는 모델 성능을 저하시킬 위험이 있었습니다.
부가 손실 없이 부하 균형을 유지하기 위해 편향 값(Bias Term)을 동적으로 조정하는 전략을 사용합니다.

2.2 Complementary Sequence-Wise Auxiliary Loss (보조 시퀀스 손실)
- 부가 손실 없는 부하 균형 전략이 전체적으로는 잘 작동하지만, 개별 시퀀스 내에서 부하 불균형이 발생할 수 있습니다.
- 이를 방지하기 위해, 시퀀스 단위에서 부하 균형을 유지하기 위한 추가적인 보조 손실을 도입했습니다.

3. Node-Limited Routing (노드 제한 라우팅)
- 중 상위 Kr/MK_r/M 점수를 가진 전문가들이 할당된 노드에서만 토큰이 라우팅 됩니다.
- 이를 통해 노드 간 통신 비용을 줄이고, 계산-통신 오버랩을 극대화합니다.
4. No Token-Dropping (토큰 드롭 없음)
DeepSeek-V3는 효과적인 부하 균형 전략 덕분에 토큰 드롭 없이 학습 및 추론을 수행합니다.
- 결과: 모든 데이터를 효율적으로 활용하면서 성능 유지.
2.3. Multi-Token Prediction (MTP)

MTP는 DeepSeek-V3에서 새롭게 도입된 학습 목표로, 단일 토큰 예측을 넘어 여러 토큰을 동시에 예측하는 기법입니다. 이를 통해 모델의 학습 신호를 더 풍부하게 만들고, 데이터 효율성을 향상했습니다.
- MTP의 역할:
- 학습 신호 밀도 증가: 여러 토큰을 예측하여 더 많은 정보를 학습에 활용할 수 있습니다.
- 미래 토큰의 예측 강화: 모델이 더 나은 표현(Representation)을 사전에 계획하고 구성할 수 있도록 돕습니다.
- MTP의 구현:
- 여러 개의 MTP 모듈이 각 위치에서 추가적으로 예측할 토큰을 생성합니다.
- 각 모듈은 Transformer Block과 출력층을 공유하며, 모든 예측이 **인과적 체인(Causal Chain)**을 유지하도록 설계되었습니다.
- MTP의 학습 목표:
- 학습 과정에서 MTP는 각 예측 깊이에 대해 **교차 엔트로피 손실(Cross-Entropy Loss)**을 계산합니다.
- 모든 깊이에 대한 평균 손실을 계산해 최종 MTP 손실로 활용하며, 이는 모델의 추가 학습 목표가 됩니다.
- MTP의 추론 활용:
- MTP 모듈은 학습 시에는 활성화되지만, 추론 시에는 사용되지 않습니다.
- 또한, MTP 모듈은 추론 속도를 높이는 Speculative Decoding에 활용될 수 있습니다.

DeepSeek-V3의 학습(FB8)
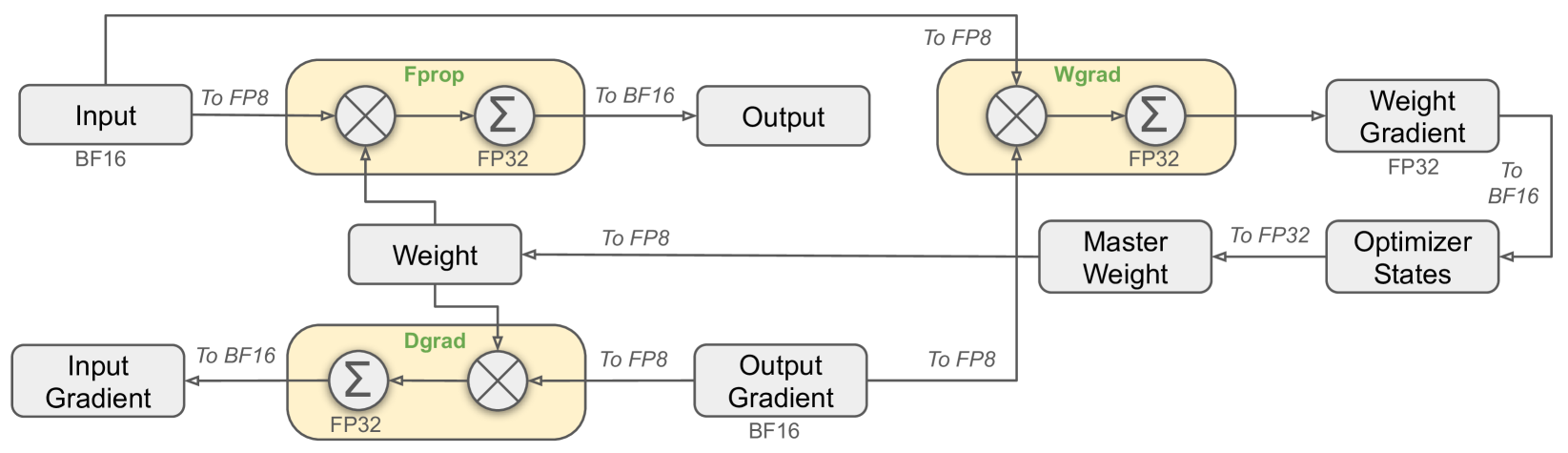
FP8(Floating Point 8-bit) Training은 모델 학습에서 FP8 정밀도를 도입하여 계산 효율성을 크게 향상하는 방법입니다. 이 기법은 메모리 사용량과 계산 비용을 줄이면서도 기존 FP32, BF16 정밀도와 비교해 성능을 유지하거나 개선할 수 있습니다.
FP8 Training의 흐름도
- 입력 처리: BF16 → FP8 변환
- Forward Propagation (FP32): FP8 → FP32 연산 → BF16 변환 후 출력
- Backward Propagation (FP32): FP8 Gradient → FP32 계산 → FP8 저장
- Weight Update (FP32): FP32 Master Weight로 업데이트 → FP8 저장
FP8 Training의 장점
- 계산 효율성:
- FP8 포맷을 통해 모델 학습 속도가 크게 향상됩니다.
- 특히, 곱셈 연산이 간단해져 GPU 활용도가 높아집니다.
- 메모리 절약:
- FP8 포맷을 사용함으로써 동일한 하드웨어에서 더 큰 모델을 학습할 수 있습니다.
- 정밀도 유지:
- FP32 Master Weight와 FP32 연산을 통해 모델의 학습 성능이 보장됩니다.
4. DeepSeek-V3의 성능
1. 오픈 소스 모델과의 비교
DeepSeek-V3는 기존의 다른 오픈 소스 모델들을 압도적으로 능가하며, 다양한 언어 작업에서 업계 최고 수준의 성능을 기록했습니다.
2. 폐쇄형 모델과의 경쟁
상용 폐쇄형 모델과 비교했을 때도 성능이 대등하거나 일부 작업에서는 더 우수한 결과를 보여줍니다.

5. 코드 보기
MLA
아래 코드에 대해서는 추가적인 공부가 필요하겠지만, 핵심적인 메모리 효율성 부분이 잘 반영되어 있다는 점이 인상적이다. 특히, LoRA_RANK가 여기서 사용된다는 점이 흥미롭다. 원래는 **SFT(Supervised Fine-Tuning)**에서 추가적인 레이어 학습에 주로 사용되던 기술이었지만, 이렇게 모델 내부 연산에서도 활용될 수 있다는 점이 눈에 띈다.
class MLA(nn.Module):
"""
Multi-Headed Attention Layer (MLA).
Attributes:
dim (int): Dimensionality of the input features.
n_heads (int): Number of attention heads.
n_local_heads (int): Number of local attention heads for distributed systems.
q_lora_rank (int): Rank for low-rank query projection.
kv_lora_rank (int): Rank for low-rank key/value projection.
qk_nope_head_dim (int): Dimensionality of non-positional query/key projections.
qk_rope_head_dim (int): Dimensionality of rotary-positional query/key projections.
qk_head_dim (int): Total dimensionality of query/key projections.
v_head_dim (int): Dimensionality of value projections.
softmax_scale (float): Scaling factor for softmax in attention computation.
"""
def __init__(self, args: ModelArgs):
super().__init__()
self.dim = args.dim
self.n_heads = args.n_heads
self.n_local_heads = args.n_heads // world_size
self.q_lora_rank = args.q_lora_rank
self.kv_lora_rank = args.kv_lora_rank
self.qk_nope_head_dim = args.qk_nope_head_dim
self.qk_rope_head_dim = args.qk_rope_head_dim
self.qk_head_dim = args.qk_nope_head_dim + args.qk_rope_head_dim
self.v_head_dim = args.v_head_dim
if self.q_lora_rank == 0:
self.wq = ColumnParallelLinear(self.dim, self.n_heads * self.qk_head_dim)
else:
self.wq_a = Linear(self.dim, self.q_lora_rank)
self.q_norm = RMSNorm(self.q_lora_rank)
self.wq_b = ColumnParallelLinear(self.q_lora_rank, self.n_heads * self.qk_head_dim)
self.wkv_a = Linear(self.dim, self.kv_lora_rank + self.qk_rope_head_dim)
self.kv_norm = RMSNorm(self.kv_lora_rank)
self.wkv_b = ColumnParallelLinear(self.kv_lora_rank, self.n_heads * (self.qk_nope_head_dim + self.v_head_dim))
self.wo = RowParallelLinear(self.n_heads * self.v_head_dim, self.dim)
self.softmax_scale = self.qk_head_dim ** -0.5
if args.max_seq_len > args.original_seq_len:
mscale = 0.1 * args.mscale * math.log(args.rope_factor) + 1.0
self.softmax_scale = self.softmax_scale * mscale * mscale
if attn_impl == "naive":
self.register_buffer("k_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.qk_head_dim), persistent=False)
self.register_buffer("v_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.v_head_dim), persistent=False)
else:
self.register_buffer("kv_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.kv_lora_rank), persistent=False)
self.register_buffer("pe_cache", torch.zeros(args.max_batch_size, args.max_seq_len, self.qk_rope_head_dim), persistent=False)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
"""
Forward pass for the Multi-Headed Attention Layer (MLA).
Args:
x (torch.Tensor): Input tensor of shape (batch_size, seq_len, dim).
start_pos (int): Starting position in the sequence for caching.
freqs_cis (torch.Tensor): Precomputed complex exponential values for rotary embeddings.
mask (Optional[torch.Tensor]): Mask tensor to exclude certain positions from attention.
Returns:
torch.Tensor: Output tensor with the same shape as the input.
"""
bsz, seqlen, _ = x.size()
end_pos = start_pos + seqlen
if self.q_lora_rank == 0:
q = self.wq(x)
else:
q = self.wq_b(self.q_norm(self.wq_a(x)))
q = q.view(bsz, seqlen, self.n_local_heads, self.qk_head_dim)
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
q_pe = apply_rotary_emb(q_pe, freqs_cis)
kv = self.wkv_a(x)
kv, k_pe = torch.split(kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
k_pe = apply_rotary_emb(k_pe.unsqueeze(2), freqs_cis)
if attn_impl == "naive":
q = torch.cat([q_nope, q_pe], dim=-1)
kv = self.wkv_b(self.kv_norm(kv))
kv = kv.view(bsz, seqlen, self.n_local_heads, self.qk_nope_head_dim + self.v_head_dim)
k_nope, v = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
k = torch.cat([k_nope, k_pe.expand(-1, -1, self.n_local_heads, -1)], dim=-1)
self.k_cache[:bsz, start_pos:end_pos] = k
self.v_cache[:bsz, start_pos:end_pos] = v
scores = torch.einsum("bshd,bthd->bsht", q, self.k_cache[:bsz, :end_pos]) * self.softmax_scale
else:
wkv_b = self.wkv_b.weight if self.wkv_b.scale is None else weight_dequant(self.wkv_b.weight, self.wkv_b.scale, block_size)
wkv_b = wkv_b.view(self.n_local_heads, -1, self.kv_lora_rank)
q_nope = torch.einsum("bshd,hdc->bshc", q_nope, wkv_b[:, :self.qk_nope_head_dim])
self.kv_cache[:bsz, start_pos:end_pos] = self.kv_norm(kv)
self.pe_cache[:bsz, start_pos:end_pos] = k_pe.squeeze(2)
scores = (torch.einsum("bshc,btc->bsht", q_nope, self.kv_cache[:bsz, :end_pos]) +
torch.einsum("bshr,btr->bsht", q_pe, self.pe_cache[:bsz, :end_pos])) * self.softmax_scale
if mask is not None:
scores += mask.unsqueeze(1)
scores = scores.softmax(dim=-1, dtype=torch.float32).type_as(x)
if attn_impl == "naive":
x = torch.einsum("bsht,bthd->bshd", scores, self.v_cache[:bsz, :end_pos])
else:
x = torch.einsum("bsht,btc->bshc", scores, self.kv_cache[:bsz, :end_pos])
x = torch.einsum("bshc,hdc->bshd", x, wkv_b[:, -self.v_head_dim:])
x = self.wo(x.flatten(2))
return xMOE
전문가 레이어(Expert Layer)가 생각보다 단순하게 구현되어 있다는 점이 매우 흥미로웠다. 각 전문가가 독립적으로 입력을 처리하며, 계산 구조는 간단하지만 효율적으로 설계되어 있어 실제로 얼마나 강력한 성능을 낼 수 있는지 궁금해진다.
특히 눈에 띄는 점은, 이 Expert 레이어가 모델의 맨 마지막에만 배치되는 것이 아니라, 각 Block의 Feed-Forward Network (FFN)을 대신하여 중간중간에 적절히 배치된다는 점이다. 이는 각 Block에서 다양한 전문가가 데이터의 특징을 학습할 수 있도록 설계된 것으로 보인다.
결과적으로, 이러한 구조는 특정 Task나 데이터에 최적화된 전문가를 동적으로 활성화함으로써 학습 효율성을 높이고 모델의 유연성을 극대화할 수 있다는 점에서 매우 인상 깊었다.
class Expert(nn.Module):
"""
Expert layer for Mixture-of-Experts (MoE) models.
Attributes:
w1 (nn.Module): Linear layer for input-to-hidden transformation.
w2 (nn.Module): Linear layer for hidden-to-output transformation.
w3 (nn.Module): Additional linear layer for feature transformation.
"""
def __init__(self, dim: int, inter_dim: int):
"""
Initializes the Expert layer.
Args:
dim (int): Input and output dimensionality.
inter_dim (int): Hidden layer dimensionality.
"""
super().__init__()
self.w1 = Linear(dim, inter_dim)
self.w2 = Linear(inter_dim, dim)
self.w3 = Linear(dim, inter_dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Forward pass for the Expert layer.
Args:
x (torch.Tensor): Input tensor.
Returns:
torch.Tensor: Output tensor after expert computation.
"""
return self.w2(F.silu(self.w1(x)) * self.w3(x))
class MoE(nn.Module):
"""
Mixture-of-Experts (MoE) module.
Attributes:
dim (int): Dimensionality of input features.
n_routed_experts (int): Total number of experts in the model.
n_local_experts (int): Number of experts handled locally in distributed systems.
n_activated_experts (int): Number of experts activated for each input.
gate (nn.Module): Gating mechanism to route inputs to experts.
experts (nn.ModuleList): List of expert modules.
shared_experts (nn.Module): Shared experts applied to all inputs.
"""
def __init__(self, args: ModelArgs):
"""
Initializes the MoE module.
Args:
args (ModelArgs): Model arguments containing MoE parameters.
"""
super().__init__()
self.dim = args.dim
assert args.n_routed_experts % world_size == 0
self.n_routed_experts = args.n_routed_experts
self.n_local_experts = args.n_routed_experts // world_size
self.n_activated_experts = args.n_activated_experts
self.experts_start_idx = rank * self.n_local_experts
self.experts_end_idx = self.experts_start_idx + self.n_local_experts
self.gate = Gate(args)
self.experts = nn.ModuleList([Expert(args.dim, args.moe_inter_dim) if self.experts_start_idx <= i < self.experts_end_idx else None
for i in range(self.n_routed_experts)])
self.shared_experts = MLP(args.dim, args.n_shared_experts * args.moe_inter_dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Forward pass for the MoE module.
Args:
x (torch.Tensor): Input tensor.
Returns:
torch.Tensor: Output tensor after expert routing and computation.
"""
shape = x.size()
x = x.view(-1, self.dim)
weights, indices = self.gate(x)
y = torch.zeros_like(x)
counts = torch.bincount(indices.flatten(), minlength=self.n_routed_experts).tolist()
for i in range(self.experts_start_idx, self.experts_end_idx):
if counts[i] == 0:
continue
expert = self.experts[i]
idx, top = torch.where(indices == i)
y[idx] += expert(x[idx]) * weights[idx, top, None]
z = self.shared_experts(x)
if world_size > 1:
dist.all_reduce(y)
return (y + z).view(shape)
MoE는 Gate와 Expert의 협력을 통해 데이터를 효율적으로 처리합니다. Gate는 데이터를 적절한 Expert로 라우팅 하고, 선택된 Expert는 독립적으로 작업을 수행합니다. 이를 통해 모델은 계산 효율성과 학습 성능을 동시에 잡을 수 있습니다. 특히, 모델의 중간 Block마다 Expert를 배치하는 방식은 데이터를 단계적으로 분석하며 더 깊이 학습하도록 도와줍니다.
더 많은 내용이 있지만, 우선은 너무 길어지고 관심이 있는 부분에 대해서만 작성하였습니다.
아마 FP8로 학습하는 것을 봐야 하겠지만 실제 깃헙 링크를 보니 Inference 부분만 있어서, 학습하는 부분은 추가로 찾아봐야 할 것 같습니다.
DeepSeek-R1
1. 개요
최근 발표된 R1 모델은 대규모 언어 모델(LLM) 설계와 학습 기술에서 새로운 패러다임을 제시했습니다. 특히, DeepSeek R1 시리즈는 기존 모델 대비 성능과 효율성을 동시에 개선하며, 학습 기술 및 추론 효율성에서의 혁신을 보여줍니다.
특히 후처리(Post-Training)는 학습 파이프라인에서 중요한 요소로 자리 잡고 있습니다. 이는 상대적으로 적은 자원으로도 추론 정확도를 향상하고, 사회적 가치와 사용자 선호도에 맞게 모델을 조정할 수 있는 잠재력을 제공합니다.
DeepSeek-R1 모델은 이러한 추세 속에서 강화 학습(Reinforcement Learning, RL)만을 활용하여 모델의 추론 성능을 발전시킨 혁신적인 사례입니다.
2. 기술적 혁신
2.1. Pure RL을 통한 순수 추론 학습
- 기존 모델들은 **Supervised Fine-Tuning (SFT)**을 필수적으로 활용하여 초기 성능을 확보하는 방식이 일반적이었습니다.
- DeepSeek-R1의 R1-Zero는 SFT 없이 **강화 학습(RL)**만으로 추론 능력을 발전시킨 최초의 공개 연구 사례입니다.
- DeepSeek-V3-Base 모델을 기반으로, GRPO(Generalized Reinforcement Policy Optimization)를 적용하여 학습.
- RL 과정에서 자기 검증(Self-Verification), 반성(Reflection), 긴 Chain-of-Thought(CoT) 생성과 같은 고급 추론 능력을 학습.
- 성과:
- AIME 2024 벤치마크에서 Pass@1 점수가 15.6% → 71.0%로 대폭 향상.
- 다수결(Majority Voting)을 적용하면 점수가 86.7%에 도달하며, OpenAI o1 모델과 동등한 성능을 기록.
2.2. 다단계 학습 파이프라인
DeepSeek-R1 모델은 대규모 언어 모델의 추론(reasoning) 능력을 강화하기 위해 새로운 학습 접근 방식을 제안했습니다.
이전 연구들이 대규모 지도 학습(Supervised Fine-Tuning, SFT) 데이터에 의존했다면, DeepSeek-R1은 순수 강화 학습(Reinforcement Learning, RL)으로 추론 성능을 발전시키는 혁신적 접근을 시도합니다.
다음의 주요 세 가지 목표를 중심으로 설계되었습니다:
- DeepSeek-R1-Zero: SFT 없이 순수 RL로 기초 모델의 추론 능력을 강화.
- DeepSeek-R1: SFT를 포함한 초기 데이터로 모델 안정성과 성능 향상을 극대화.
- 추론 증류: 대규모 모델의 추론 능력을 소형 밀집(Dense) 모델에 전이(Distill).

DeepSeek-R1은 추론 성능을 극대화하기 위해 다단계 학습 파이프라인을 도입하였습니다:
- 초기 데이터 수집(Cold-Start Data):
- DeepSeek-V3-Base 모델을 소량의 SFT 데이터로 미세 조정.
- 강화 학습 1단계:
- R1-Zero와 동일한 방식으로 추론 중심의 강화 학습을 수행.
- SFT 데이터 확장:
- 강화 학습에서 생성된 데이터를 선별(Rejection Sampling)하고, 기존 SFT 데이터를 추가하여 새롭게 Fine-Tuning.
- 강화 학습 2단계:
- 최종적으로 모든 시나리오에 대응하는 RL을 적용하여 DeepSeek-R1 모델 완성.
이러한 파이프라인은 모델의 추론 능력뿐만 아니라 비추론적 작업(예: 글쓰기, QA 등)에서도 높은 성능을 유지하도록 설계되었습니다.
2.3. Distillation(지식 증류)
- DeepSeek-R1에서 발견된 고급 추론 패턴을 더 작은 밀집 모델(Dense Models)에 전이(Distill)하여 효율성과 성능을 동시에 달성.
- 성과:
- Qwen2.5-32B와 Llama 시리즈를 기반으로, 다양한 크기의 모델(1.5B ~ 70B)을 성공적으로 증류.
- Distilled 14B 모델이 QwQ-32B-Preview를 능가하는 결과를 기록하며, 소형 모델에서도 높은 성능을 입증.
3. 접근 방식
위에서 2.2의 파이프라인에서 말한 것처럼 단계별로 개발한 것에 대한 내용입니다.
DeepSeek-R1 접근 방식은 아래와 같은 단계로 구성됩니다:
- DeepSeek-R1-Zero: SFT 데이터를 전혀 사용하지 않고, RL로 기초 모델을 직접 학습.
- DeepSeek-R1: SFT로 수집한 소량의 고품질 데이터를 통해 기초 모델을 미세 조정(Fine-Tune)한 뒤 RL로 성능을 최적화.
- 추론 증류: DeepSeek-R1에서 학습된 고급 추론 패턴을 소형 모델로 전이.
3.1 DeepSeek-R1-Zero: 순수 강화 학습
3.1.1 Group Relative Policy Optimization (GRPO) 알고리즘
DeepSeek-R1-Zero는 강화 학습 효율성을 위해 GRPO 알고리즘을 사용합니다.
GRPO의 주요 특징은 Critic 모델 없이 그룹 점수를 기반으로 학습한다는 점입니다. 이 접근법은 학습 비용을 줄이면서도 높은 성능을 제공합니다.
GRPO 알고리즘의 목표 함수는 다음과 같이 정의됩니다:
그룹의 정의
- 하나의 질문 (q): 정책 모델이 처리해야 할 입력 질문입니다.
- 출력 그룹: 질문 q에 대해 정책 모델 πold\pi_{\text{old}}이 생성한 여러 개의 출력 (o1,o2,…,oGo_1, o_2, \ldots, o_G)으로 구성됩니다.
-

- 예를 들어, qq가 "2+2는 얼마인가?"라는 질문이라면, 출력 그룹은 모델이 생성한 다음과 같은 여러 답변이 될 수 있습니다:
- o1="4"o_1 = "4"
- o2="4입니다."o_2 = "4입니다."
- o3="답은4입니다."o_3 = "답은 4입니다."
- o4="정확히4."o_4 = "정확히 4."
- 예를 들어, qq가 "2+2는 얼마인가?"라는 질문이라면, 출력 그룹은 모델이 생성한 다음과 같은 여러 답변이 될 수 있습니다:

이 접근법은 RL의 안정성과 성능을 동시에 달성하며, 복잡한 추론 문제에 최적화된 모델을 생성합니다.

3.1.2 보상 모델링 (Reward Modeling)
DeepSeek-R1-Zero는 두 가지 주요 보상 체계를 활용합니다:
- 정확도 보상(Accuracy Rewards): 응답의 정확도를 평가합니다.
- 수학 문제: 정답을 규칙 기반 검증 시스템(예: 컴파일러, 테스트 케이스)으로 평가.
- LeetCode 문제: 컴파일 결과로 정답 여부 확인.
- 형식 보상(Format Rewards): 모델이 추론 과정을 <think> 태그로 구분하고, 최종 응답을 <answer>로 명확히 표시하도록 학습.
3.2 DeepSeek-R1: Cold Start와 다단계 학습
데이터 설계의 의의
- Cold Start 데이터: RL 학습 초기의 불안정을 제거하고, 모델의 초기 성능을 가독성 및 사용자 친화적인 형태로 보장.
- Reasoning 데이터: 정확도와 논리적 정합성을 보장하면서 모델의 논리 추론 성능을 극대화.
- Non-Reasoning 데이터: 다목적 성능을 강화하고, 사용자 경험을 개선하는 데 기여.
- 전체 데이터 설계:
- 초기 단계에서 가독성 높은 데이터를 수집하여 기반을 다지고, 후속 단계를 통해 다양한 도메인과 작업에 대한 일반적 성능을 강화.
DeepSeek-R1 데이터 설계 및 구성 요약
| 데이터 유형 | 목적 | 구성 방법 | 규모 | 특징 |
| Cold Start 데이터 | 초기 RL 학습 불안정성을 제거하고 초기 모델 수렴을 가속화 | - Few-shot Prompting: Long CoT 예제를 활용 - 직접 생성: 자세한 답변 유도 및 수집 - DeepSeek-R1-Zero 출력 활용: 읽기 쉬운 형식으로 정제 및 후처리 |
수천 개 | - 가독성 높은 출력 (Markdown 스타일 포함) - 요약 추가 (<reasoning_process> + <summary> 구조) - 혼합 언어 및 복잡한 포맷 제거 |
| Reasoning 데이터 | 수학, 과학, 코딩 등 논리적 추론 작업의 성능 강화 | - Rejection Sampling: 정확한 응답만 선별 - 규칙 기반 평가: 수학 결과 검증 및 컴파일러 테스트 활용 - 모델 기반 평가: DeepSeek-V3로 생성 결과 정제 - 혼합 언어 및 코드 블록 필터링 |
약 60만 개 | - 정확성 강화 - 혼합 언어, 긴 문단 및 복잡한 코드 블록 제거 - RL 체크포인트에서 생성된 데이터를 기반으로 정제 |
| Non-Reasoning 데이터 | 일반 작업(작성, 번역, 질문 응답 등)의 성능 강화 | - DeepSeek-V3 파이프라인 재사용 - 간단한 질문: CoT 없이 간결한 응답 제공 - 복잡한 질문: CoT를 포함한 상세 답변 생성 |
약 20만 개 | - 다목적 작업 강화 - 간단한 질문은 빠른 응답 제공 - 복잡한 작업에 대한 CoT 생성 및 정제 |
| 통합 데이터 | Reasoning 및 Non-Reasoning 데이터 통합, 다양한 작업 성능 최적화 | - Reasoning 데이터와 Non-Reasoning 데이터를 통합 - 총 약 80만 개의 데이터셋 구성 |
약 80만 개 | - 2 에포크 동안 Fine-tuning - 논리적 추론과 다목적 작업 성능을 동시에 강화 |
핵심 특징
3.2.1 Cold Start 데이터
DeepSeek-R1은 소량의 고품질 데이터(SFT)를 사용하여 초기 RL 안정성을 보장합니다.
- Cold Start 데이터 설계:
- 추론 과정(CoT)을 명확히 포함하는 데이터 수집.
- 인간 주석을 통해 읽기 쉬운 출력 패턴 생성.
3.2.2 Reasoning 중심 RL
SFT로 초기 모델을 학습한 뒤, DeepSeek-R1-Zero와 동일한 RL 프로세스를 적용하여 추론 능력을 강화했습니다.
- 언어 일관성(Language Consistency) 보상을 추가해 다국어 혼합 문제 해결.
3.2.3 Rejection Sampling과 추가 SFT
RL로 수집한 데이터를 선별하여 80만 개의 고품질 데이터를 확보.
- 약 60만 개: 수학, 코딩, 논리 등 추론 중심 데이터.
- 약 20만 개: 글쓰기, 번역 등 일반 작업 데이터.
3.3.4 전방위 RL
최종 RL 단계에서는 모든 시나리오에 대응하는 모델을 학습.
- 도움 및 무해성 평가:
- 도움이 되는 응답(Helpful)과 안전한 응답(Harmless)을 평가 및 최적화.
3.4. Distillation(추론 증류)
DeepSeek-R1은 대형 모델의 추론 능력을 소형 모델로 효율적으로 증류(distillation) 하는 방식을 제시하며, 계산 비용을 절감하면서도 높은 성능을 유지합니다.
핵심 요약
- 목적:
- 대형 모델의 고급 추론 능력을 소형 모델로 이전하여, 효율적이고 가벼운 모델 개발.
- 사용된 기본 모델:
- Qwen: Qwen2.5-Math-1.5B~32B
- Llama: Llama-3.1-8B, Llama-3.3-70B
- Llama-3.3은 더 나은 추론 성능으로 선택됨.
- 학습 데이터셋:
- 약 800k 샘플:
- 600k 추론 데이터: 수학, 논리, 코딩 중심.
- 200k 비추론 데이터: 작문, 번역 등.
- 약 800k 샘플:
- 학습 방법:
- **Supervised Fine-Tuning (SFT)**만 사용, RL 단계 생략.
- 비용 절감과 효율성 강조.
주요 결과와 의의
- 추론 성능:
- Qwen-32B, Qwen-7B 등 소형 모델에서 최고 수준의 추론 성능 달성.
- 효율성과 강력한 성능의 균형.
- 확장성:
- 리소스가 제한된 환경에서도 활용 가능하며, 배포 용이.
- 오픈소스 기여:
- 연구 커뮤니티에 공개되어 추가 연구와 활용 가능성 확대.
아래 성능을 보면, 경량화된 모델도 좋은 성능을 내는 것을 확인할 수 있습니다

4. DeepSeek-R1의 성능
4.1. 추론 관련 태스크
- AIME 2024: 79.8% (Pass@1)로 OpenAI-o1-1217을 약간 상회.
- MATH-500: 97.3%로 OpenAI-o1-1217과 동등하며, 기타 모델들을 크게 상회.
- 코딩 태스크: Codeforces 대회에서 96.3%의 인간 참가자를 능가하는 2,029 Elo 점수 기록.
4.2. 지식 관련 태스크
- MMLU: 90.8%, MMLU-Pro: 84.0%, GPQA Diamond: 71.5%로 DeepSeek-V3 대비 성능 대폭 향상.
- Factual QA(SimpleQA): DeepSeek-V3를 능가하며, 사실 기반 쿼리에 강력한 처리 능력을 보여줌.
4.3. 기타 태스크
- AlpacaEval 2.0: 길이 제어된 태스크에서 87.6% 승률 기록.
- ArenaHard: 92.3% 승률로 비시험 태스크에서도 강력한 성능을 발휘.
- 긴 문맥 이해(Long-Context): DeepSeek-V3를 대폭 상회하며 긴 문맥 처리에서도 탁월한 성능을 보여줌.


R1 요약

개인 생각
요즘 유튜브와 여러 플랫폼에서 화제가 되고 있는 DeepSeek에 대해 알아보았습니다.
DeepSeek 모델은 중국에서 개발되었다는 점에서 글로벌 시장에서 신뢰와 채택에 있어 도전 과제를 안고 있을 가능성이 있지만, 기술적인 측면에서는 상당히 혁신적이고 효율적이라는 점에서 주목할 만합니다. 특히, 리소스를 최소화하면서 높은 성능을 내는 방법론을 도입한 점은 매우 인상적입니다.
제가 직접 웹에서 DeepSeek 모델을 테스트해본 결과, Claude와 유사한 프롬프트를 입력했을 때 거의 동일한 결과를 얻을 수 있었습니다. 이는 DeepSeek이 기존의 주요 AI 모델과 경쟁 가능한 수준의 성능을 제공한다는 것을 보여줍니다.
더 놀라운 점은, DeepSeek의 모델이 상대적으로 저렴한 비용으로 운영될 수 있다는 점입니다. 이는 가격 경쟁력과 운영 효율성 측면에서 매력적인 옵션이 될 수 있음을 의미합니다. 특히 기업들이 AI 도입 비용을 절감하려는 상황에서, DeepSeek은 주목받는 선택지가 될 가능성이 높습니다.
물론, 보안과 데이터 주권에 대한 우려가 있을 수 있지만, 이러한 부분만 잘 해결된다면, DeepSeek은 글로벌 AI 시장에서 상당한 영향력을 발휘할 수 있을 것으로 보입니다.
앞으로 DeepSeek의 실제 서비스화와 사용 사례가 더 많아진다면, AI 기술의 접근성과 효율성을 크게 개선할 수 있는 중요한 기술로 자리잡을 것 같습니다.
https://www.deepseek.com/
관련 링크
| Name | LINK |
| DeepSeek-V3 Technical Report Paper | https://arxiv.org/html/2412.19437v1#S3 |
| DeepSeek-R1 Paper | https://arxiv.org/html/2501.12948v1 |
| github-deepseek-r1-code | https://github.com/huggingface/open-r1 |
| github-deepseek-v3-code | https://github.com/deepseek-ai/DeepSeek-V3/tree/main/inference |
| deepseek-r1-description | https://aipapersacademy.com/deepseek-r1/ |
| DEEPSEEK | https://www.deepseek.com/ |
'재태크의 하루' 카테고리의 다른 글
| [AI]퍼플렉시티(Perplexity AI) 무료와 Pro 차이점 (0) | 2025.02.03 |
|---|---|
| 딥시크 어플 다운로드 방법 (7) | 2025.02.01 |
| 34년만의 슈퍼엔저 기록 : 일본 엔화 (0) | 2024.07.06 |
| 미국 금리 인하 전망 : FOMC 주목해야하는 이유 (0) | 2024.07.06 |
| 비트코인 이해하기: 디지털 혁명의 선두주자(알트코인) (1) | 2024.07.06 |





댓글